































Tech | 03/19/2026
Merkle Tree & HSM: Scaling Ledger Enterprise Security
Discover how Ledger Enterprise overcomes HSM storage limits by evolving from monotonic counters to sparse Merkle trees for scalable institutional custody.
TL;DR
The Problem:
- Ledger Enterprise initially protected governance objects using per-object monotonic counters inside HSMs to prevent replay attacks.
- This approach faced a scalability wall because HSM secure memory is too limited to store a counter for every object as the platform grows.
The Solution:
- The architecture migrated to a sparse Merkle tree design, reducing the HSM storage requirement to a single 32-byte root hash per customer.
The Result:
- Sparse Merkle trees allow the HSM to verify the integrity and versioning of billions of objects stored in external databases.
- This shift allows the HSM to act as a pure trust anchor, providing massive scalability while preserving hardware-enforced security guarantees.
From Monotonic Counters to Merkle Trees
Ledger Enterprise provides a technical & secure infrastructure used by institutions such as DAOs, asset managers, exchanges and banks to secure billions of dollars worth of digital assets.
At this scale, security assumptions change. A single seed protected by a single signer (even when backed by secure hardware) is neither scalable nor resilient against operational risk, insider threats, or governance failures. Large organizations require self-custody at scale, where cryptography enforces governance rules beyond individual devices or users.
Ledger Enterprise (formerly Ledger Vault) was built to meet these requirements. In this post, we explain how Ledger Enterprise uses Hardware Security Modules (HSMs) to enforce governance, why it historically relied on monotonic counters to prevent replay attacks, and how it evolved toward a Merkle tree-based design to overcome the scalability limits of secure hardware.
Context & Issues: Governance at scale and the HSM Constraints
Institutional Custody requires Hardware-enforced governance
Ledger Enterprise is Ledger’s digital asset platform designed for institutions. It combines secure hardware, cryptography, and governance workflows to ensure that no single actor can unilaterally move funds, while still enabling organizations to operate efficiently and with full control over their assets.
Unlike consumer wallets or purely non-custodial platforms, institutional custody must support multi-user access, role separation, approval workflows, insider threat mitigation, and auditability. Online custody platforms introduce custodial risk by placing asset control in the hands of third parties, while a single hardware signer remains a single point of failure and cannot enforce organizational governance.
Ledger’s security philosophy is simple: never compromise. This naturally made secure hardware the foundation of the entire Ledger ecosystem.
Secure Hardware is not a database
At the core of Ledger Enterprise is the use of Hardware Security Modules (HSMs) and Ledger’s proprietary OS for HSMs: LEOS (Ledger Enclave Operating System). HSMs are secure hardware devices that store cryptographic keys and execute security-critical operations in isolation. They provide a small amount of internal secure storage, enforce cryptographic confidentiality, integrity and authenticity of externally stored data, and protect sensitive operations from both external attackers and insider threats.
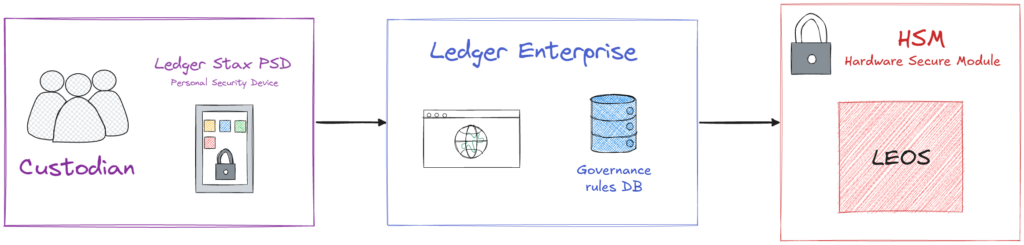
In Ledger Enterprise, all critical operations, such as verifying permissions or validating governance rules, are enforced by the HSM. This provides strong security guarantees, but also introduces a fundamental constraint.
The replay problem in external storage
HSMs are secure by design, but they have an important downside: their internal secure memory is very limited (only a few megabytes), which makes storing large amounts of data inside the HSM impractical.
At the same time, Ledger Enterprise must manage a growing amount of governance objects per customer, such as user groups, permissions, and policies (in short, the rules that define who can do what). As a result, most governance objects are stored outside the HSM, in databases, either encrypted (to guarantee both confidentiality and authenticity) or signed (to guarantee authenticity only).
This raises a critical question:
How do we prevent an attacker from replaying an old, but valid, version of a governance object?
This issue is also known as a “replay attack”.
To defend against these replay attacks without compromising hardware integrity, our initial architecture relied on a dedicated hardware-enforced counting mechanism.
First Architecture: Monotonic Counters
Per-object versioning with monotonic counters
To address the “replay attack” problem, Ledger Enterprise historically relied on a patented mechanism based on monotonic counters enforced by HSMs.
A monotonic counter is a value that can only increase. For each governance object, its counter identifier and current value are stored inside the HSM, and the same information is embedded in the encrypted or signed object stored in the external database. As a result, every object requires its own monotonic counter to be persisted in the HSM’s secure memory.
How replay attacks are prevented
Although the database is untrusted, it cannot violate security guarantees: objects are encrypted or signed, preventing content tampering or unauthorized reads in the case of confidential data, and counter values cannot be modified, reset, rolled back, or dissociated from their corresponding objects.
This is because the HSM acts as the sole source of truth and can reliably detect:
- Object tampering: encryption or signature verification failure
- Object rollback: counter value different than the trusted value
- Non-authentic objects: unknown counter identifiers or invalid signatures
Whenever an object is passed to the HSM:
- The HSM verifies the object’s integrity and authenticity
- The embedded counter identifier and value are compared against the trusted counter stored internally
- Any mismatch causes the operation to be rejected due to a suspected replay attack (re-using an old but valid version of an object to bypass a later, more restrictive rule).
When an object is updated:
- The HSM increments the associated counter
- The new counter value is stored inside the HSM
- The object is re-encrypted or re-signed with the updated counter
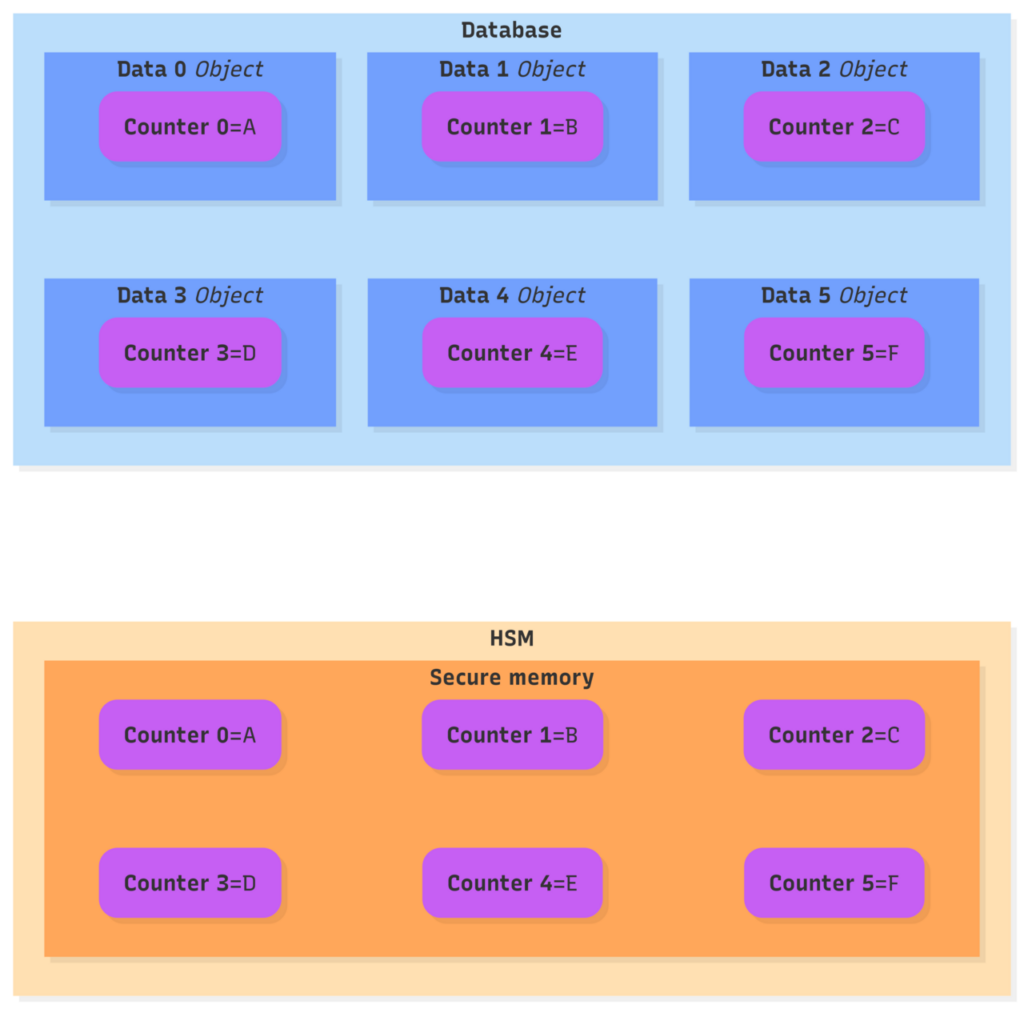
Each counter value, stored in the HSM, is tightly coupled to the value inside the corresponding object, stored externally in the database.
Example: Replay Attack on a Governance Group
Expand to see a detailed example of a Replay attack scenario
One category of governance objects in Ledger Enterprise is user groups.
A user group defines which operators, identified by their PSDs (Personal Security Devices, i.e. a Ledger Stax signer), are allowed to create or validate transactions.
Assume that a group object is at version 42, so both the HSM and the encrypted object store: counter = 42.
An operator is removed from the group. The group is thus updated to version 43.
At this point, the removed operator must no longer be able to act.
If a rogue employee attempts to replay the old version 42 object, for example to create a new transaction:
- The HSM detects a counter value mismatch
- The operation is refused
The replay attack fails.

The scalability wall
This design provides strong cryptographic replay protection and has been operating flawlessly in production for years. However, while being very effective, this design has a fundamental scalability problem:
Each unique monotonic counter needs to be stored inside the secure storage of the HSM. In other words, we need to store one monotonic counter inside the HSM secure memory for each object stored in the database.
So, as Ledger Enterprise grows with more customers, more governance objects and more features, the HSM storage footprint grows too.
Over the years, multiple iterations optimized the monotonic counters: Improved counter encoding, more efficient storage layout… But the underlying issue remained:
Secure hardware storage does not scale like databases do.
A new approach was required, one that preserved the same security guarantees while decoupling object count from HSM storage usage.
New approach: Merkle Trees
The key-idea: a single trusted commitment
Instead of storing per-object monotonic counters inside the HSM, the new design stores a single 32-byte value per customer:
The root hash of a Merkle tree.
A Merkle tree (or hash tree) is an authenticated data structure where leaf nodes contain hashes of data objects and parent nodes contain hashes of their children. The root hash uniquely commits to the entire dataset: any change to a single object alters its leaf hash, propagates upward, and ultimately changes the root. In that sense, a Merkle tree can be seen as a cryptographic hash of an entire database, while still allowing efficient, fine-grained operations.
Here, we represent a binary Merkle tree of depth 3: Each node has 2 children, with the leaves level and 2 level of nodes.
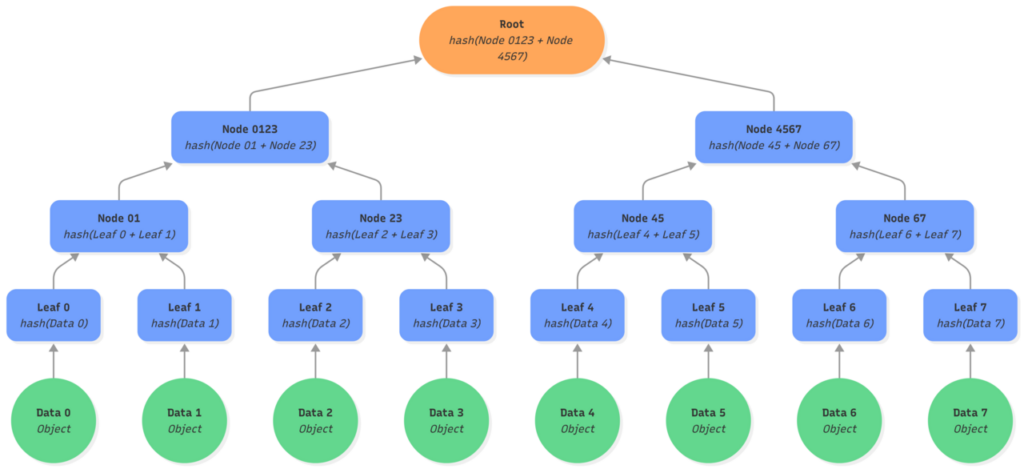
Merkle trees as authenticated data structure
Unlike a simple hash of all data objects, Merkle trees provide two properties that are essential in our architecture:
- A single object (leaf) can be updated without re-hashing the entire dataset, only the nodes on the path from the leaf to the root (also called “Merkle path”).
- A leaf can be proven to belong to the tree using a Merkle proof, without access to any other objects.
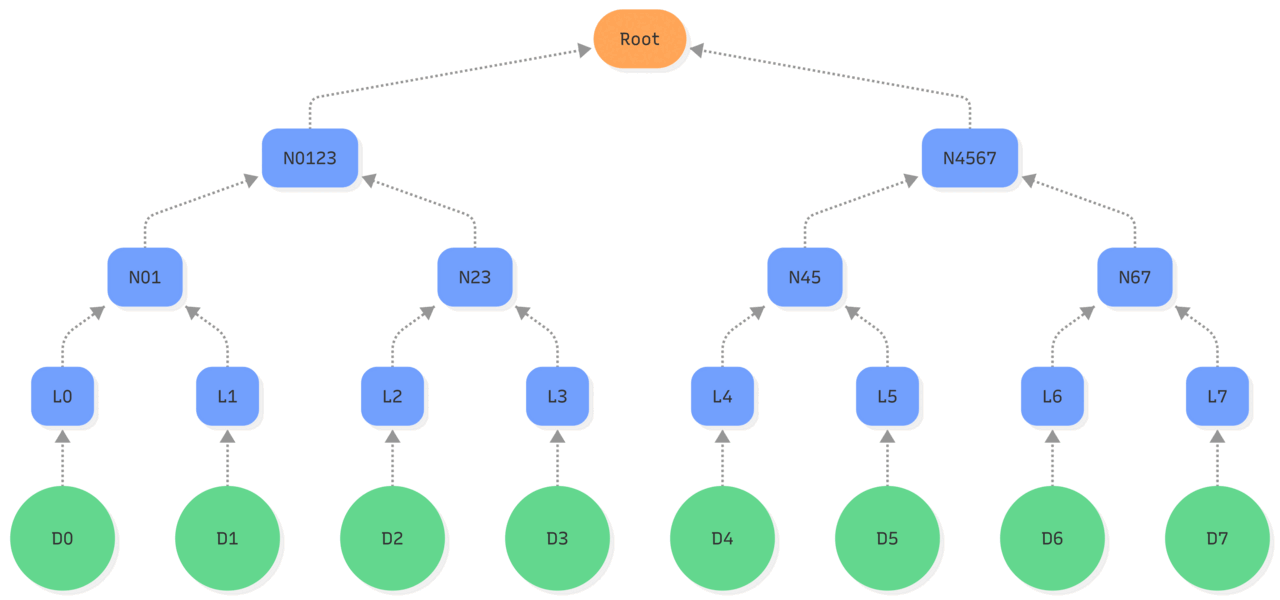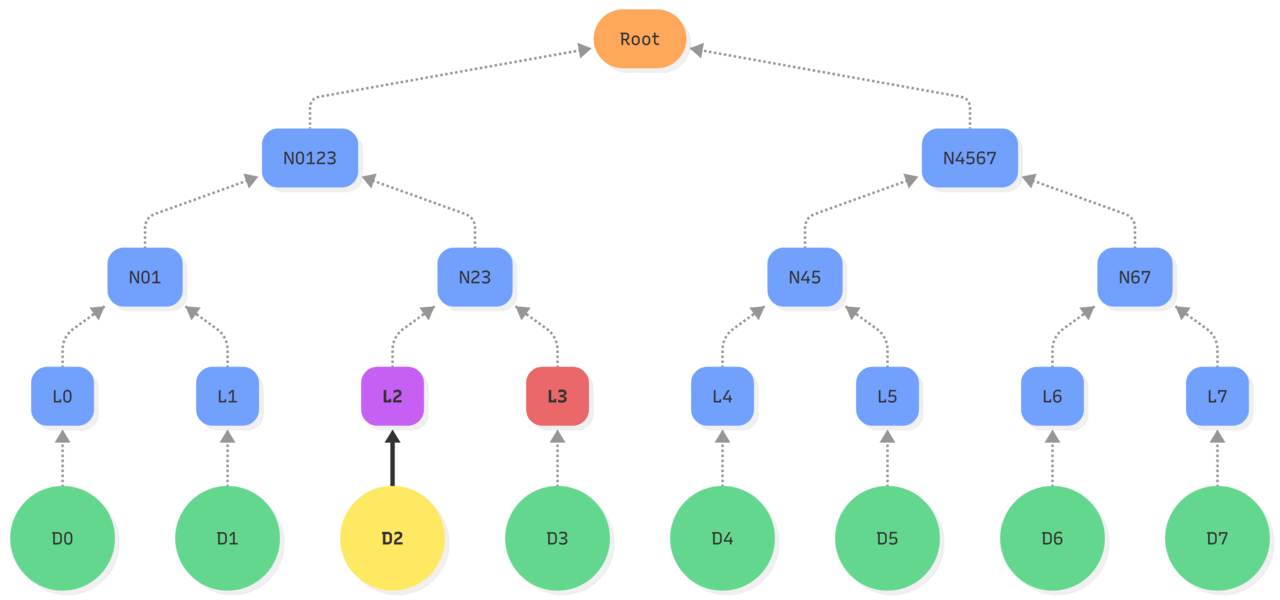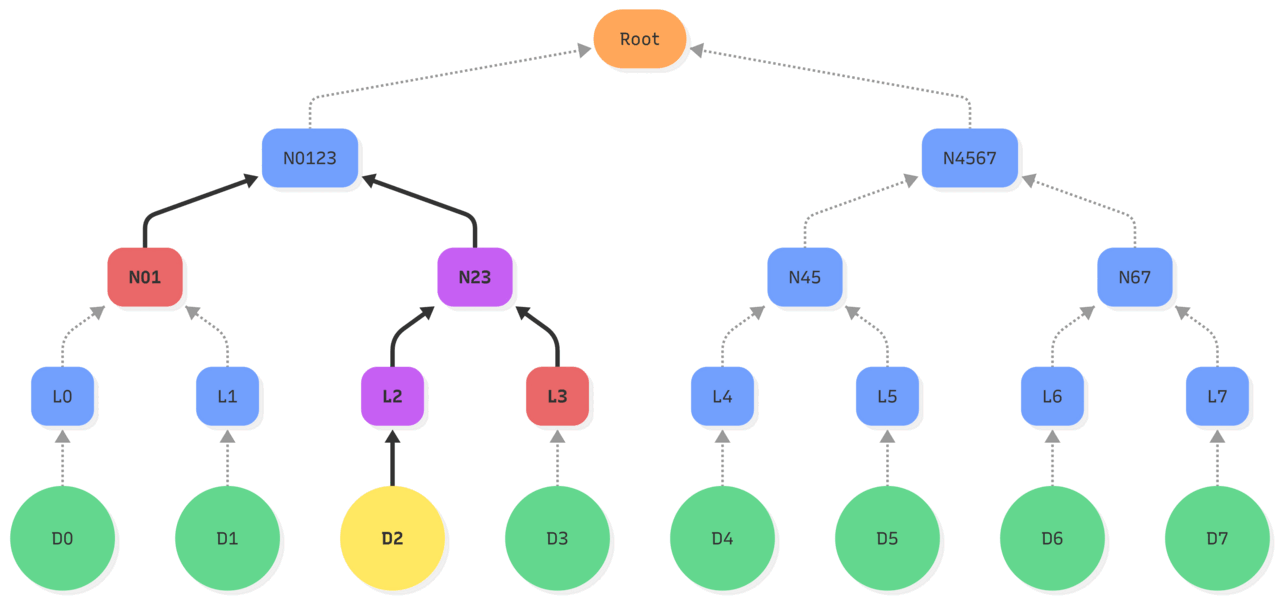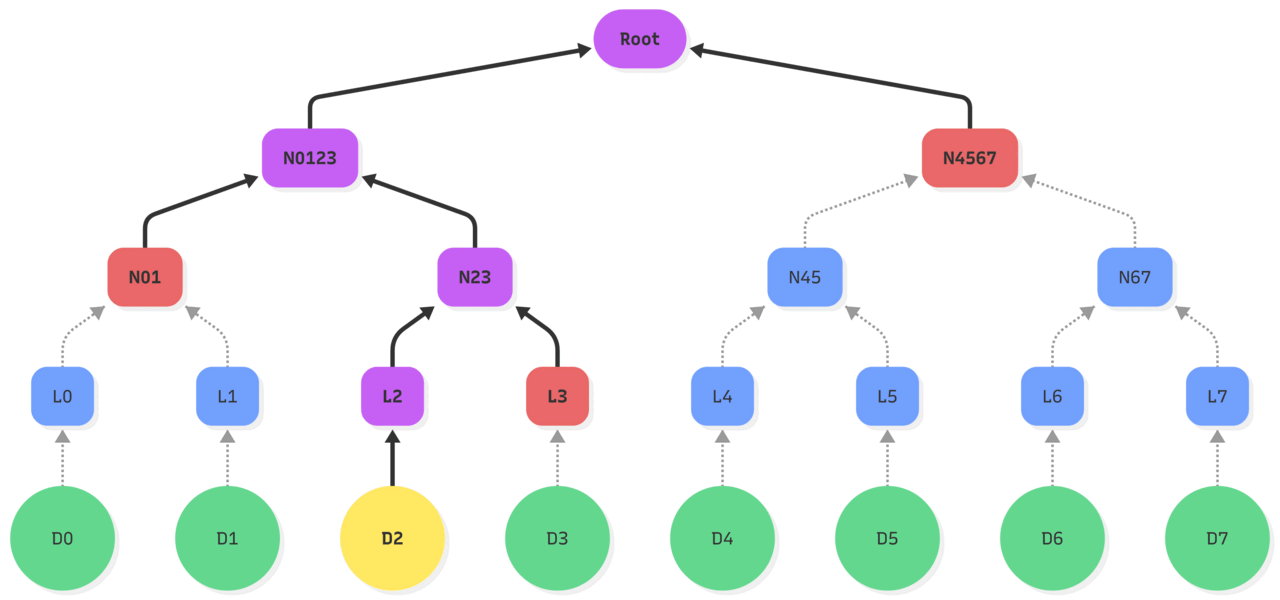
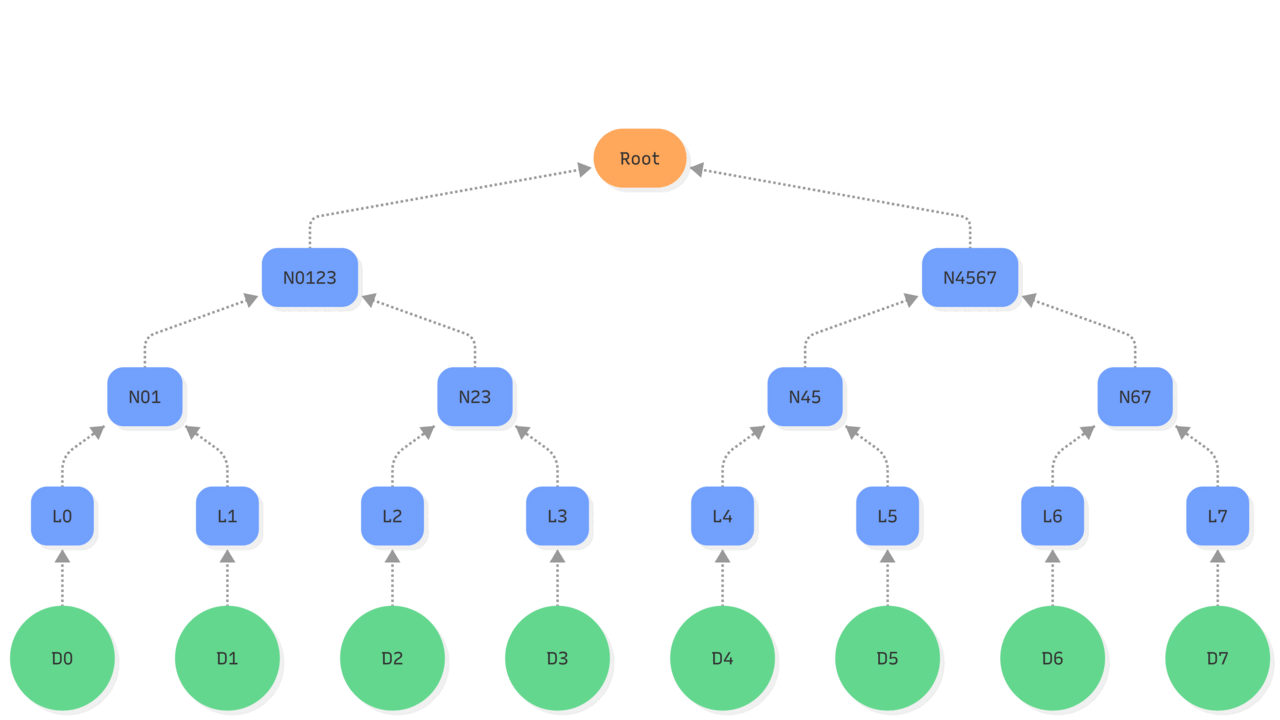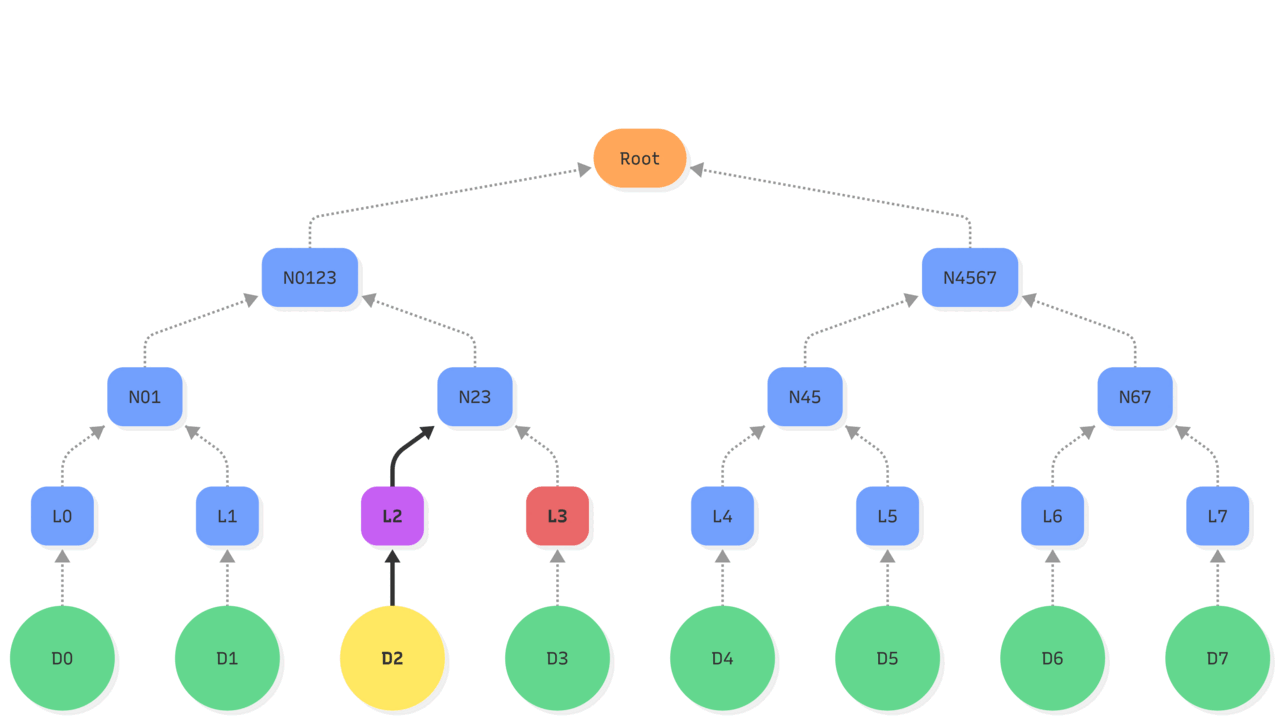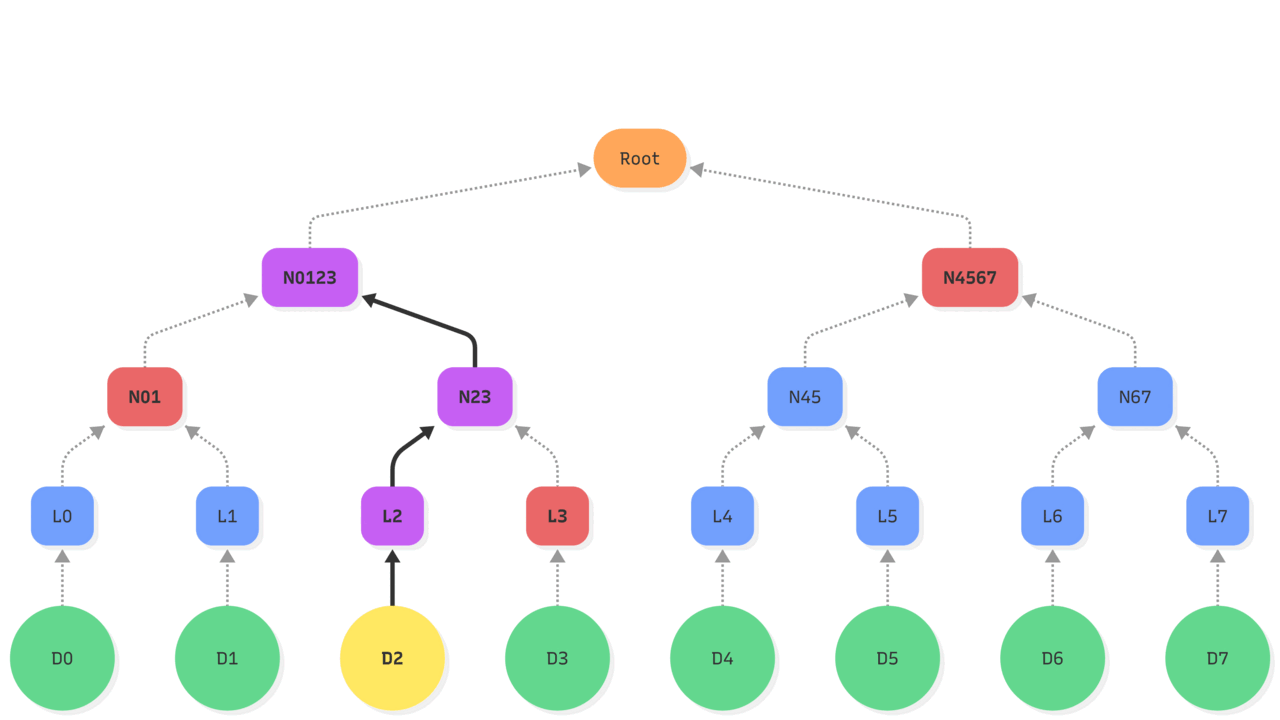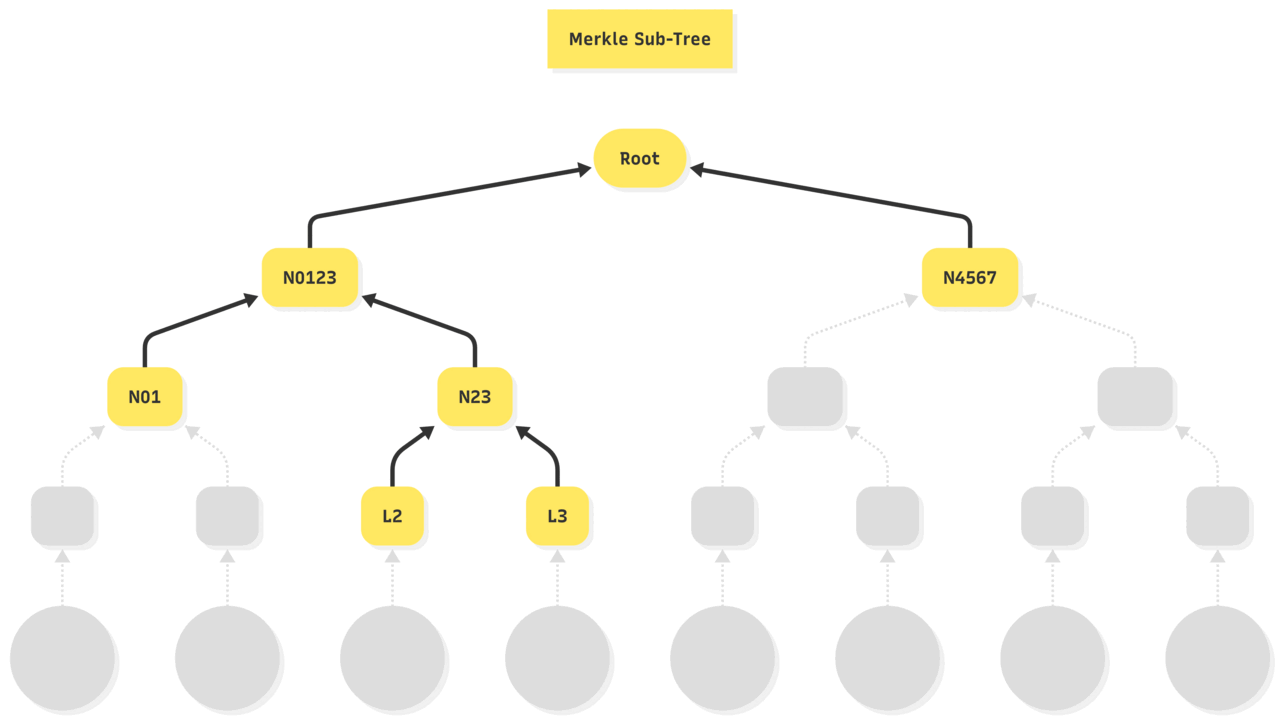
| –> : hash operations Purple: updated state Red: existing state used |
| 1. Updating the object D2 makes its hash change, so the leaf L2 is updated. 2. Leading to an update of the hash of leaf L2 and L3 stored in the node N23. 3. Which changes the node N0123 based on nodes N01 and N23. 4. Ultimately, recomputing the Root hash of the tree by hashing the new value of N0123 and the existing N4567. |
A Merkle proof consists of the minimal set of sibling hashes needed to recompute the root from a given leaf. The same mechanism also supports multi-proofs, allowing several objects to be verified and updated atomically with a single compact proof. A Merkle proof size grows logarithmically with the number of leaves, making verification efficient and well-suited for execution inside an HSM.
- The Merkle path is the set of nodes on the path from a given leaf (or set of leaves) up to the root.
- The Merkle proof consists of the sibling nodes required at each level to recompute that path.
- Together, the path and its proof form the minimal subtree needed to verify inclusion of a set of leaves, without access to the rest of the tree.
| –> : hash operations Purple: updated state Red: existing state used |
| 1. To prove that object D2 is part of the tree will require the leaf L2 to be computed. 2. The node N23 will need to be recomputed thus requiring leaf L3. 3. Like for an update of the tree, recomputing the Root hash of the tree requires N4567 and N0123 which itself depends on N01. |
Why plain Merkle trees are not enough
However, a regular Merkle tree is not sufficient for Ledger Enterprise’s use case. In a dynamic system where objects are frequently created and updated, several issues arise:
- Object creation: when an object does not yet exist, there is no leaf and therefore no inclusion proof to provide to the HSM.
- Non-deterministic topology: if the tree structure depends on insertion order, the position of a new leaf cannot be predicted by the HSM.
- Unstable mapping: mapping database object identifiers to tree positions becomes complex if the tree shape changes over time.
- No native non-existence proofs: proving that an object does not already exist is not natively supported.
These limitations prevent the HSM from safely reasoning about future object positions and make plain Merkle trees ill-suited for secure object versioning with external storage. To address this, Ledger Enterprise uses sparse Merkle trees to anchor the verification of externally stored versioned objects within an HSM.
Sparse Merkle Trees for deterministic governance
A sparse Merkle tree has a fixed and fully deterministic topology from the start.
- At the beginning all leaves and internal nodes are empty and implicitly defined as hash(0).
- Only non-default nodes are stored, meaning empty nodes do not need to be stored and can be omitted when generating a proof.
- Since the topology is known and fixed leaves can be indexed by a key (key-value semantics).
- The full path from any leaf to the root is always known.
- Proofs of non-inclusion are possible by providing a proof for an empty leaf.
This makes sparse Merkle trees particularly well-suited for HSM-based verification:
- The HSM can verify both the existence and non-existence of objects.
- Object creation is safe and deterministic.
- Hashing empty nodes is avoided through implicit defaults, reducing computation.
- Verification and updates remain logarithmic in complexity and predictable in cost.
When objects are sent to the HSM, they are hashed into leaves and combined with their Merkle proof to reconstruct the minimal subtree up to the root. During this process, empty sibling leaves and nodes, implicitly defined by the sparse Merkle tree, are omitted from hashing. The resulting root hash of the subtree is then compared with the trusted root hash stored inside the HSM, verifying that the objects indeed belong to the Merkle tree and have not been modified outside secure hardware.
In short, sparse Merkle trees preserve the cryptographic guarantees of Merkle trees while providing the determinism, scalability, and performance characteristics required to replace our legacy object versioning based on monotonic counters.
Operational Model & Tradeoffs
Monotonic Counters vs Sparse Merkle Trees
Compared to monotonic counters, the new architecture around Merkle trees introduces some overhead:
- Merkle proofs are transmitted to the HSM with each object operation
- Hash computations for verification
- Hash recomputation on updates
However, this overhead must be compared against counter-based costs:
- HSM memory performance degrades as the usage of the secure memory grows
- Replacing monotonic counters with Merkle roots reduces memory pressure and improves HSM performance
- Overhead is logarithmic
- It scales to billions of objects
- Most of the Merkle logic (e.g. recomputing the whole tree) is handled outside of the HSM, keeping execution efficient
In practice, this trades small and predictable computational overhead in the HSM for massive scalability gains.
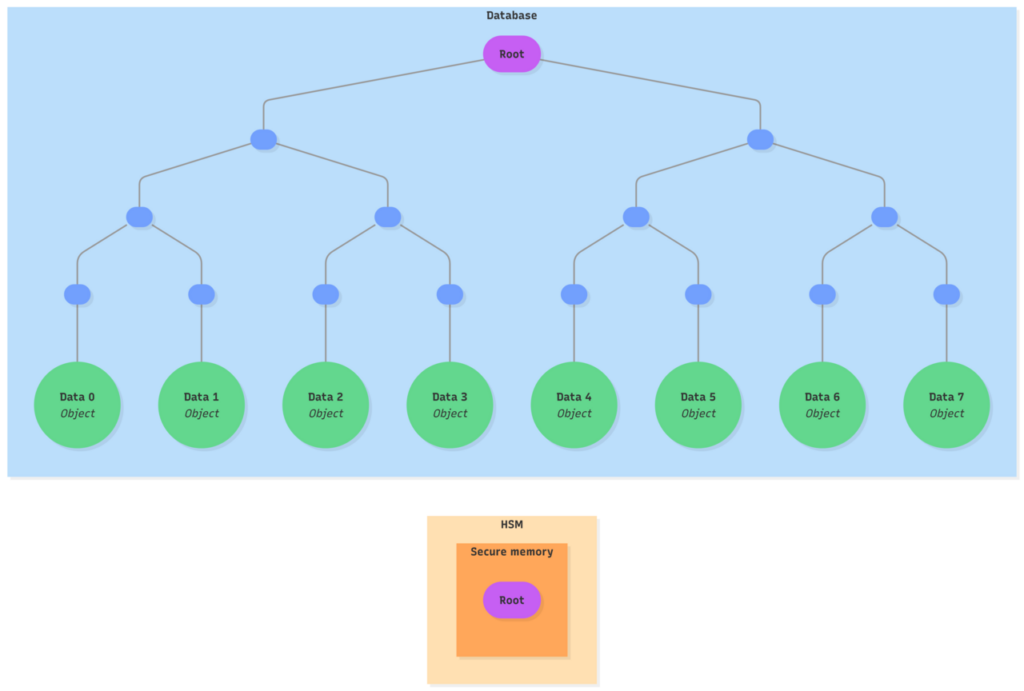
Only a single root hash needs to be stored inside the HSM. The objects and the data representing the Merkle tree are stored externally in the database.
Example: Updating an existing object and creating a new one
Expand to see a detailed example of object’s update and creation within the HSM
- The database prepares the operation:
- Retrieves the existing object data based on its object identifier
- Selects an unused object identifier
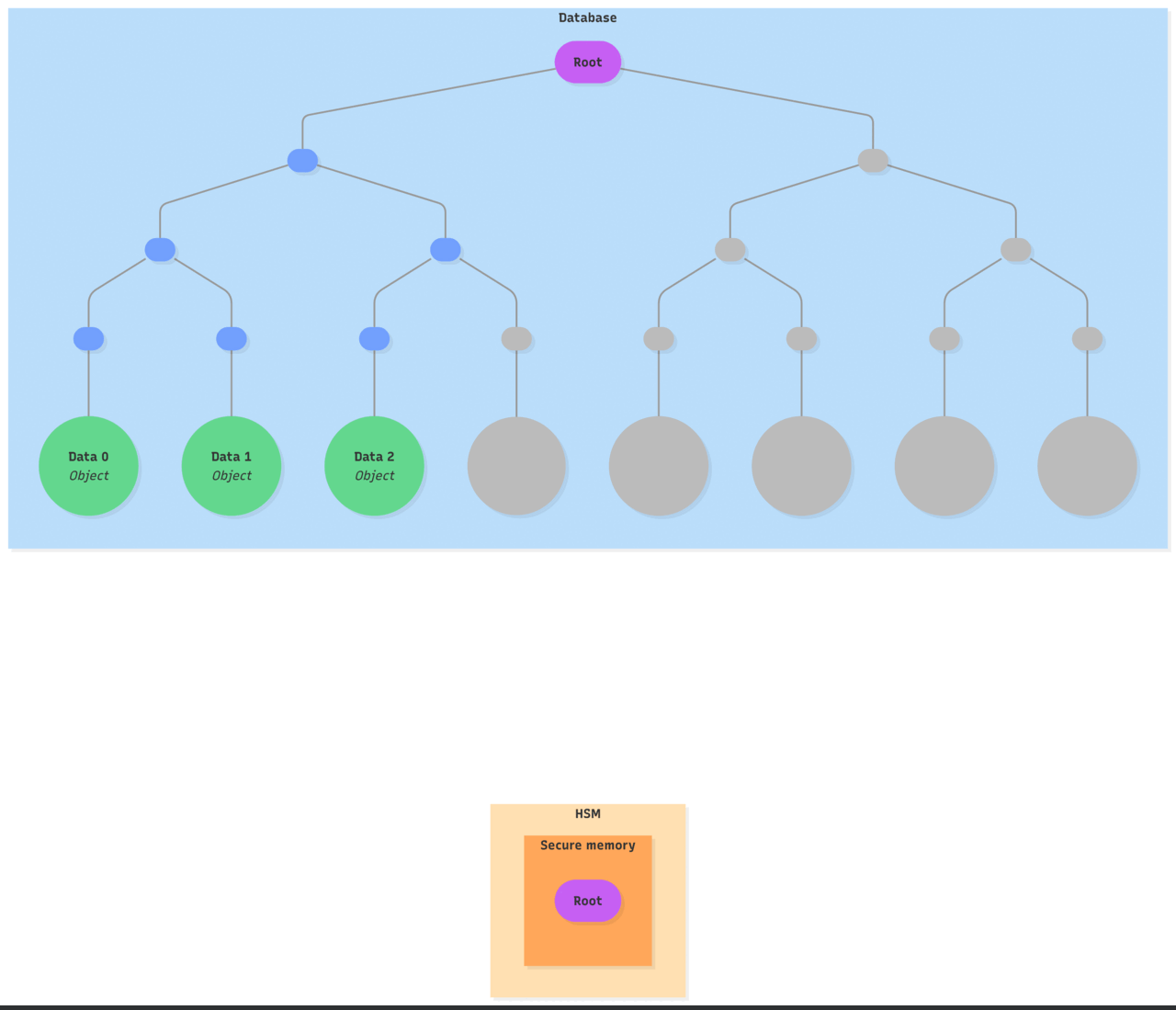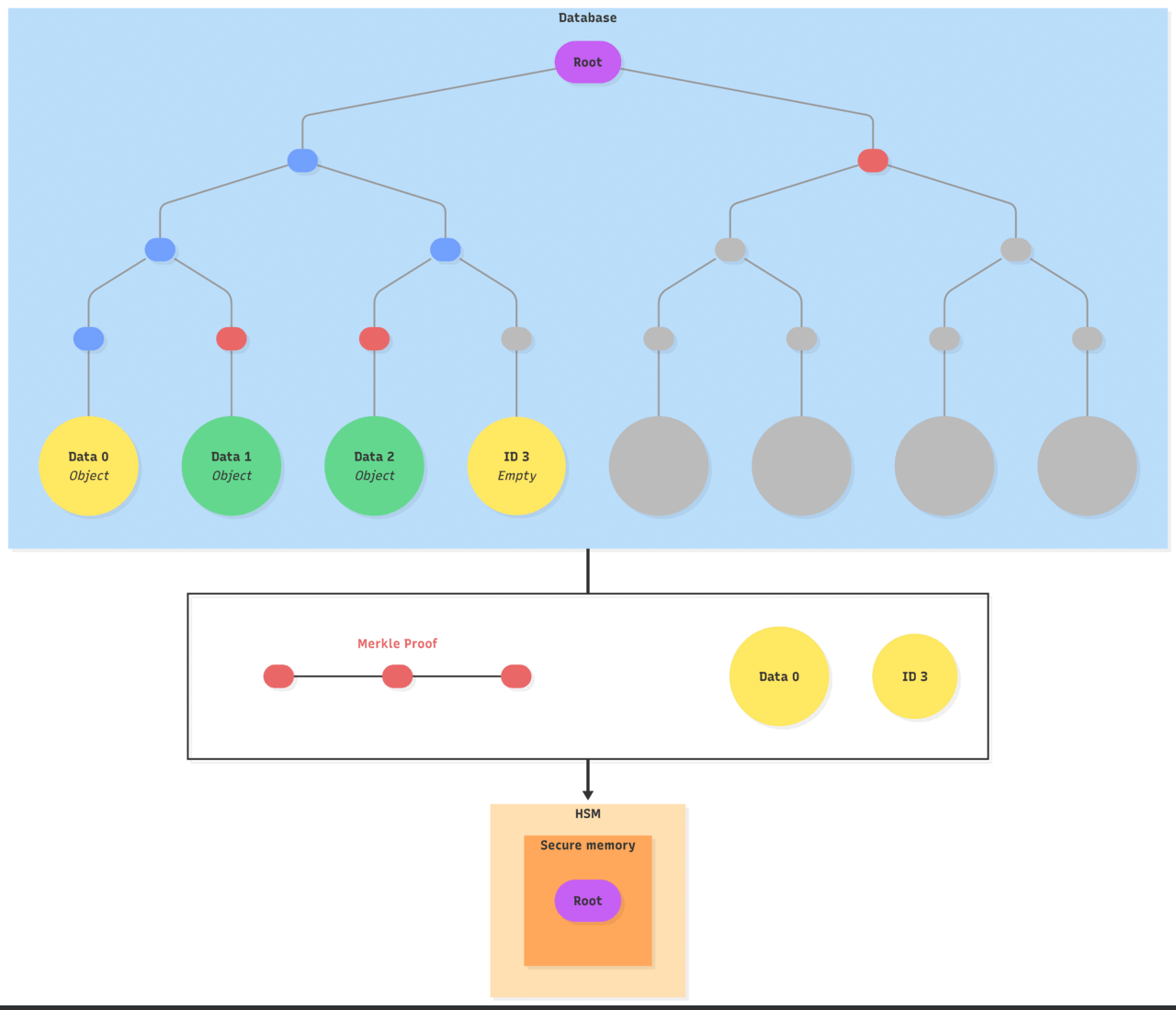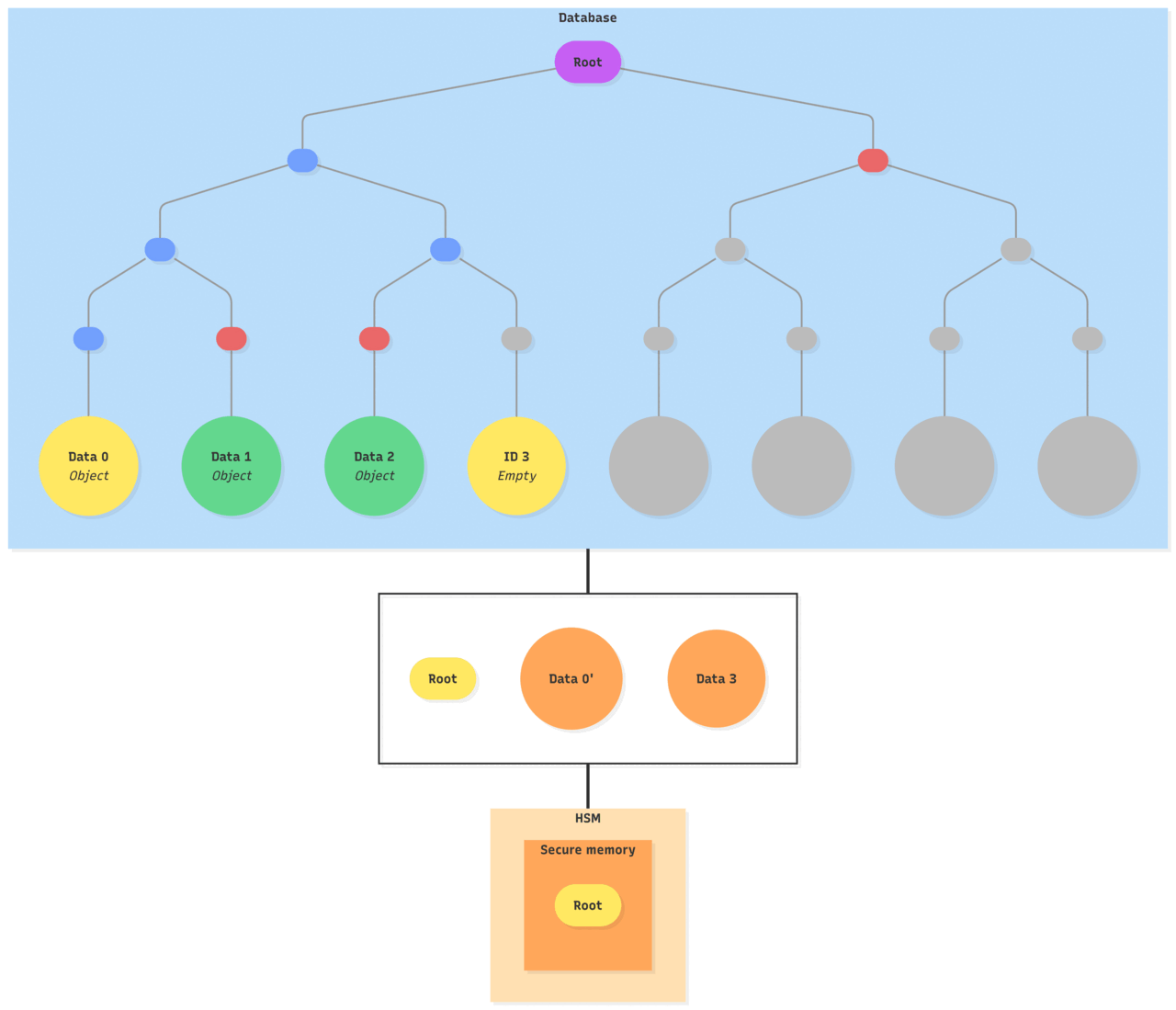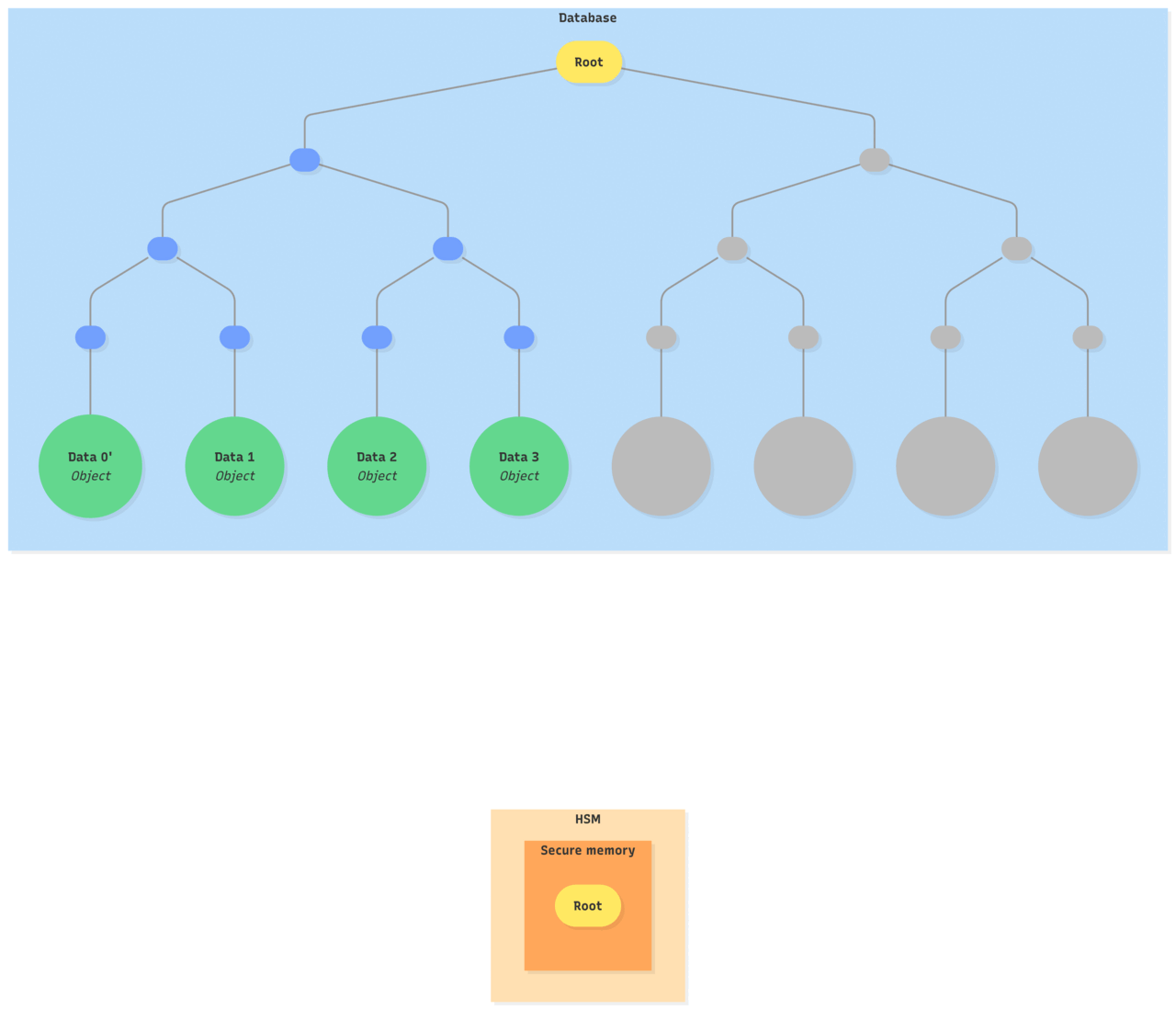
- Generates a multi-proof to prove inclusion of the existing object and non-inclusion of the new object identifier
- The database sends the request to the HSM:
- The objects identifiers
- The existing object data
- The Merkle proof
- The HSM verifies and computes the new state:
- Recomputes a sub-tree from the received objects identifiers, the existing object’s data and the proof
- Verifies the root of the sub-tree matches the root hash in its secure memory
- Authorizes the existing object to be used and the new object to be created
- The existing object is updated and the new object is created by associating some data to it
- The new root hash of the sub-tree is computed
- The HSM returns the updated state to the database:
- The objects identifiers
- The objects data
- The new Merkle root
- The database recomputes and commits:
- The database stores the objects and updates the Merkle tree
- Recomputes the tree with the updated objects data
- Verifies that the new Merkle root is the one returned by the HSM
- Once both parties agree on the new root hash
- The HSM persists it in its secure memory
- The database stores the objects and updates the Merkle tree
Scaling Without Compromise
Ledger has patented this approach of using sparse Merkle trees to version objects while relying on the HSM as the trust authority. In this design, both the objects and the full Merkle tree are stored outside secure hardware, with only the Merkle root kept as trusted state inside the HSM.
This root acts as a cryptographic commitment to the entire system state. Any operation must present a valid Merkle proof to the HSM, which verifies that the operation is consistent with the current committed state before allowing the provided data to be used. Unlike traditional approaches, the HSM never stores or accesses the full Merkle tree, yet it remains the sole authority that validates and produces state transitions. It therefore acts both as the only trust anchor and as the only trusted updater of the tree. This allows data to be stored in a database considered unsecured and untrusted.
This preserves the same replay protection and integrity guarantees as monotonic counters, while enabling horizontal scalability and constant HSM storage usage per user.
Conclusion: Breaking the Limits of Secure Hardware
Traditional secure hardware architecture relies on storing trusted state directly inside the HSM, tying scalability to the physical limits of secure memory. This model provides strong integrity and replay protection, but it makes scaling very challenging.
Ledger Enterprise’s new architecture removes this limitation. The HSM no longer needs to remember every object, it only needs to verify their integrity.
This fundamentally changes the role of secure hardware. The HSM stops being a storage bottleneck and becomes a pure trust anchor.
Security remains enforced by hardware, but scalability is no longer limited by it.
Want to learn more about Ledger Enterprise? Visit our website at: enterprise.ledger.com
Nathan BLEUZEN
Staff Firmware Engineer